- The prediction maps corresponding to the methods in Table 1 of our paper: Baidu Pan (yxy9)
- PySODEvalToolkit: A Python-based Evaluation Toolbox for Salient Object Detection and Camouflaged Object Detection
- COD Datasets
- SOD Datasets
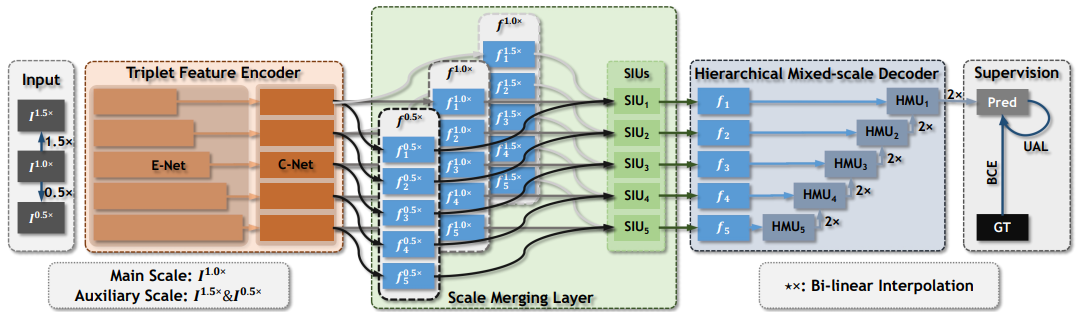
Zoom In and Out: A Mixed-scale Triplet Network for Camouflaged Object Detection
.
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2022, IEEE
.
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2022, IEEE
![]()



🖐️ BibTeX (ZoomNet-CVPR2022)
@inproceedings{ZoomNet-CVPR2022,
title = {Zoom In and Out: A Mixed-scale Triplet Network for Camouflaged Object Detection},
author = {Pang, Youwei and Zhao, Xiaoqi and Xiang, Tian-Zhu and Zhang, Lihe and Lu, Huchuan},
booktitle = CVPR,
year = {2022}
}
👋 Abstract
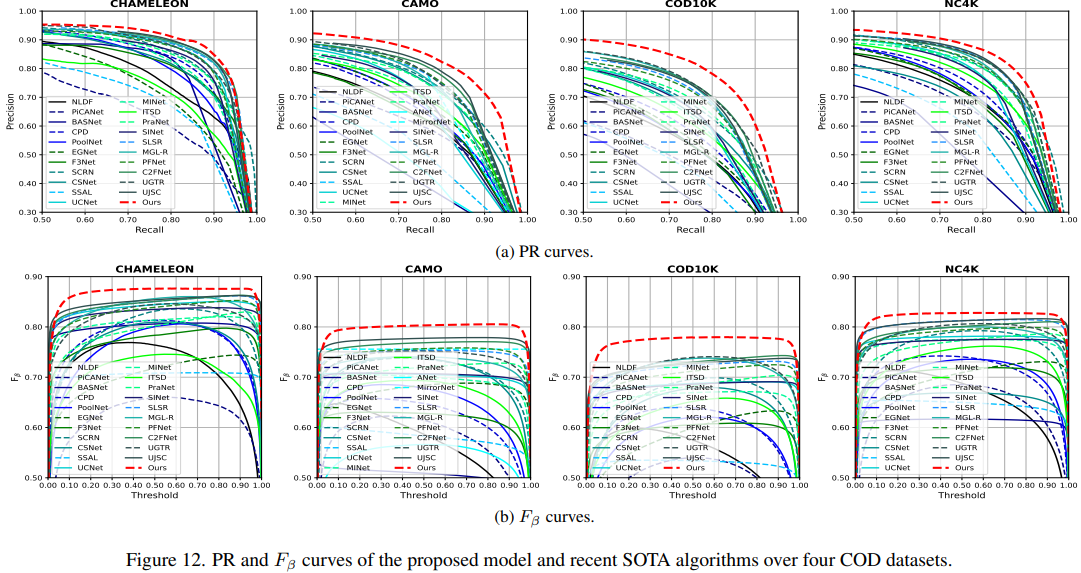
The recently proposed camouflaged object detection (COD) attempts to segment objects that are visually blended into their surroundings, which is extremely complex and difficult in real-world scenarios. Apart from high intrinsic similarity between the camouflaged objects and their background, the objects are usually diverse in scale, fuzzy in appearance, and even severely occluded. To deal with these problems, we propose a mixed-scale triplet network, \textbf{ZoomNet}, which mimics the behavior of humans when observing vague images, i.e., zooming in and out. Specifically, our ZoomNet employs the zoom strategy to learn the discriminative mixed-scale semantics by the designed scale integration unit and hierarchical mixed-scale unit, which fully explores imperceptible clues between the candidate objects and background surroundings. Moreover, considering the uncertainty and ambiguity derived from indistinguishable textures, we construct a simple yet effective regularization constraint, uncertainty-aware loss, to promote the model to accurately produce predictions with higher confidence in candidate regions. Without bells and whistles, our proposed highly task-friendly model consistently surpasses the existing 23 state-of-the-art methods on four public datasets. Besides, the superior performance over the recent cutting-edge models on the SOD task also verifies the effectiveness and generality of our model.
🔗 Related Links
| Task | Weights | Results |
|---|---|---|
| COD | GitHub Release Link | GitHub Release Link |
| SOD | GitHub Release Link | GitHub Release Link |
📖 ZoomNet
Method Details

Experiment
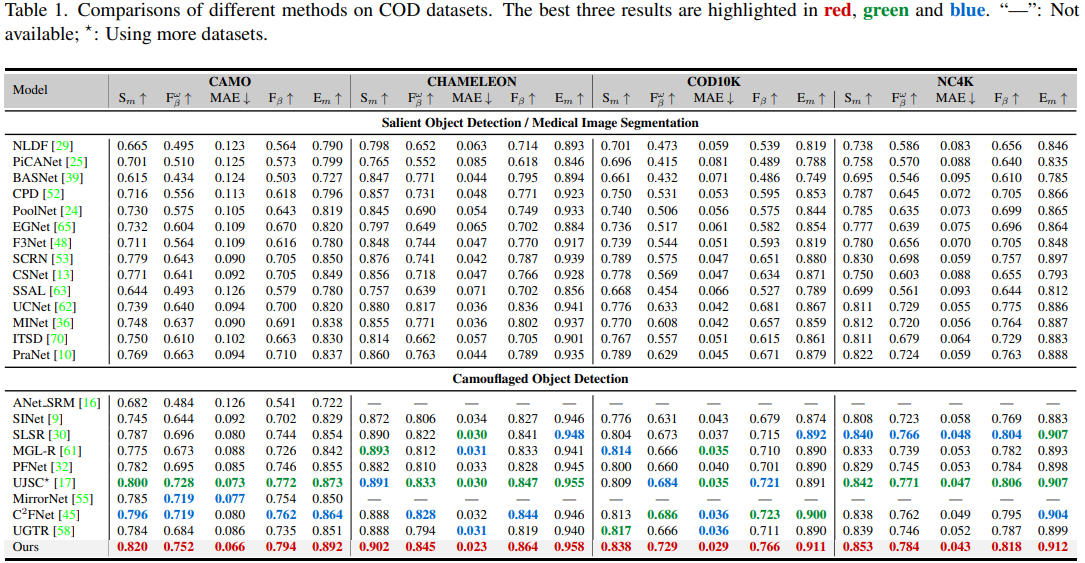
Camouflaged Object Detection

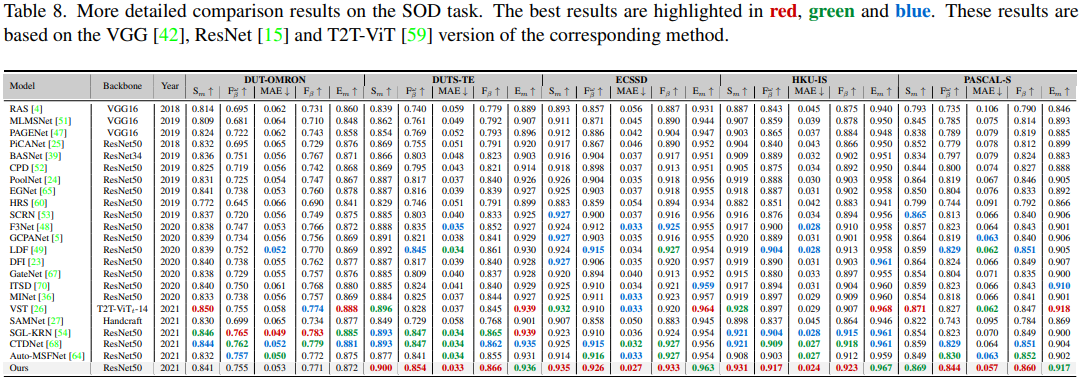
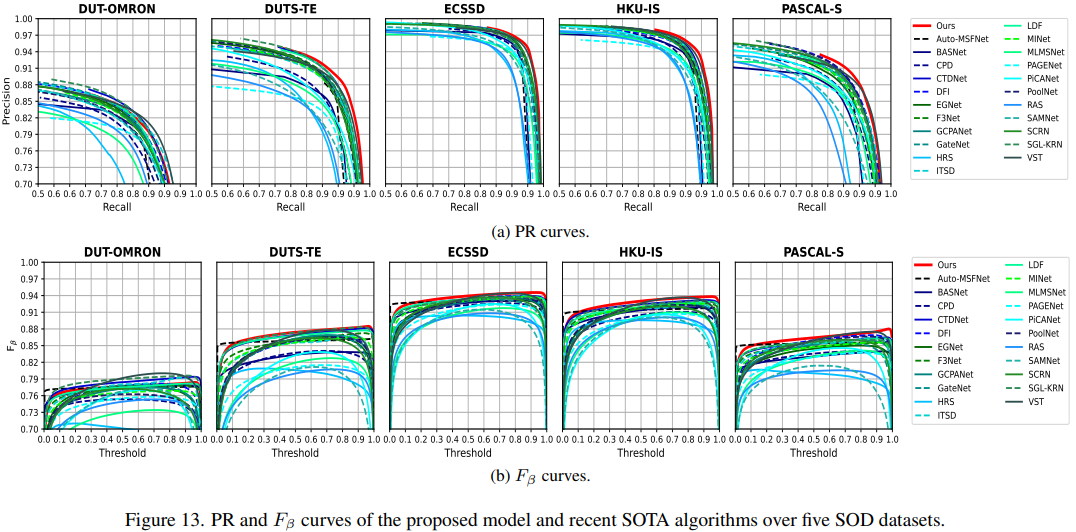
Salient Object Detection