CAVER: Cross-Modal View-Mixed Transformer for Bi-Modal Salient Object Detection



Abstract
Most of the existing bi-modal (RGB-D and RGB-T) salient object detection methods utilize the convolution operation and construct complex interweave fusion structures to achieve cross-modal information integration. The inherent local connectivity of the convolution operation constrains the performance of the convolution-based methods to a ceiling. In this work, we rethink these tasks from the perspective of global information alignment and transformation. Specifically, the proposed \underline{c}ross-mod\underline{a}l \underline{v}iew-mixed transform\underline{er} (CAVER) cascades several cross-modal integration units to construct a top-down transformer-based information propagation path. CAVER treats the multi-scale and multi-modal feature integration as a sequence-to-sequence context propagation and update process built on a novel view-mixed attention mechanism. Besides, considering the quadratic complexity w.r.t. the number of input tokens, we design a parameter-free patch-wise token re-embedding strategy to simplify operations. Extensive experimental results on RGB-D and RGB-T SOD datasets demonstrate that such a simple two-stream encoder-decoder framework can surpass recent state-of-the-art methods when it is equipped with the proposed components. Code and pretrained models will be available at https://github.com/lartpang/CAVER.
Method Details
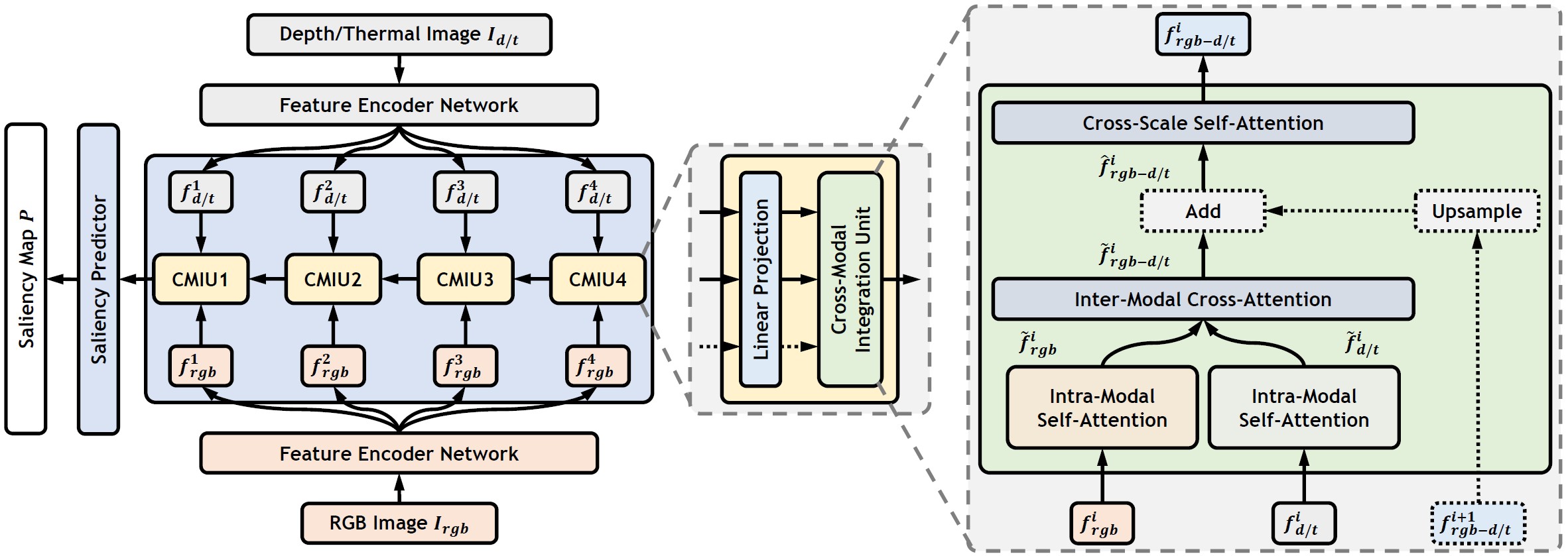
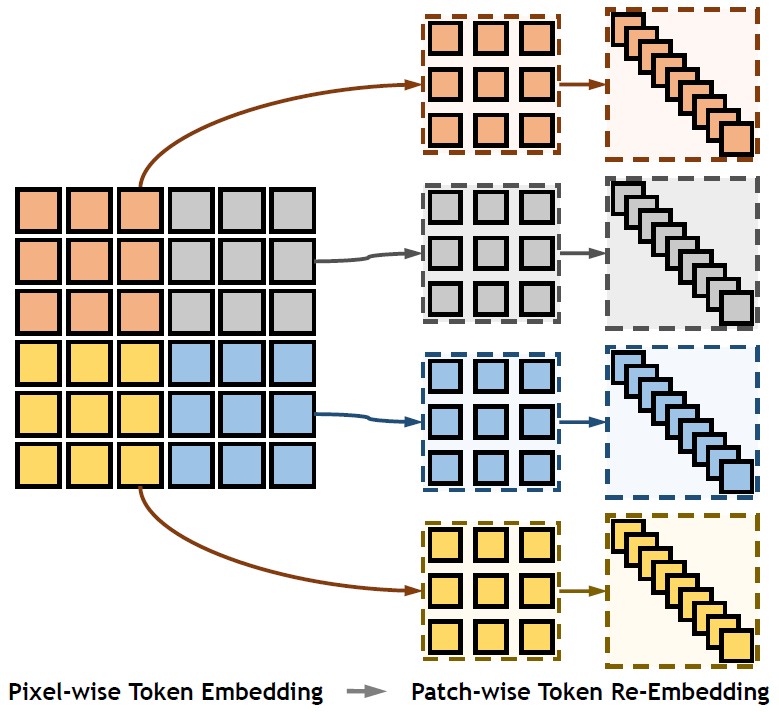
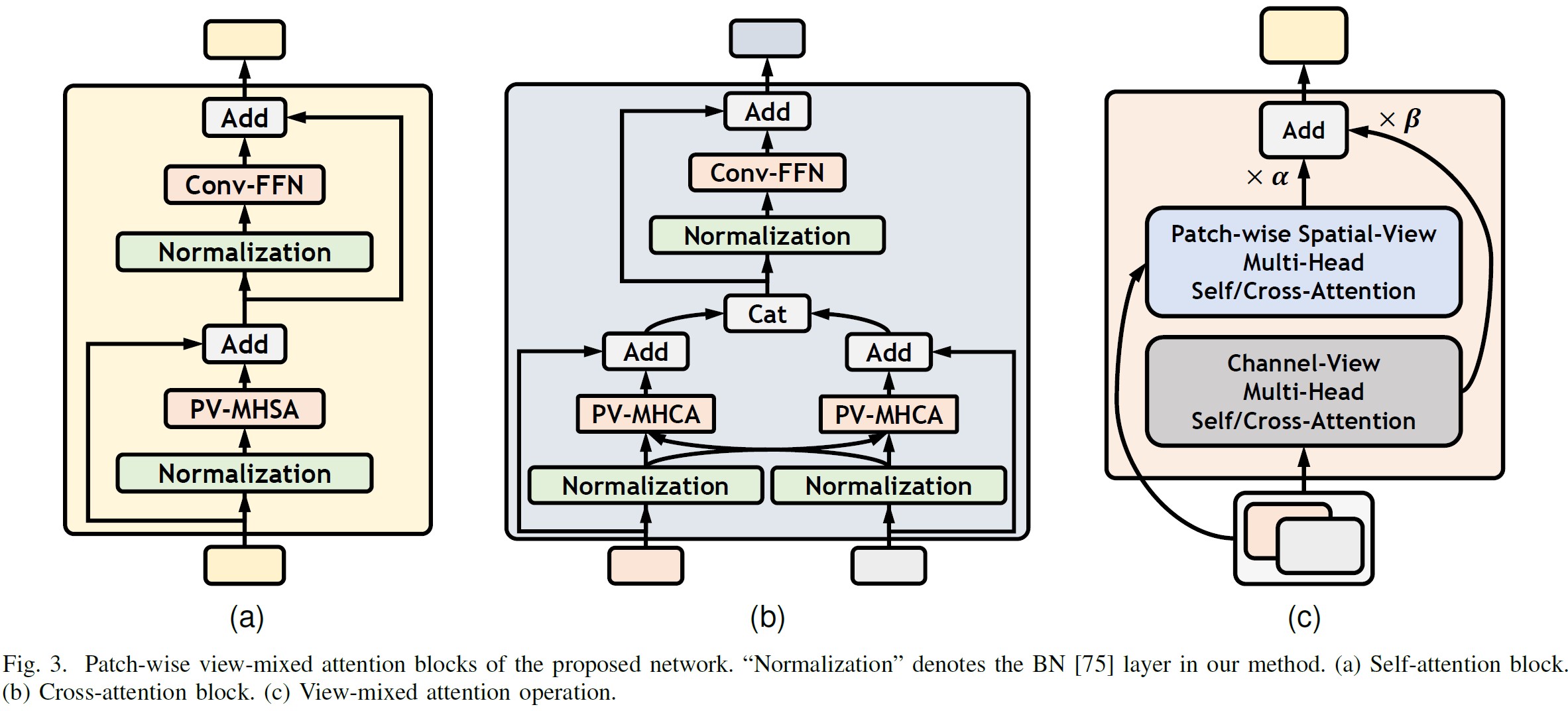
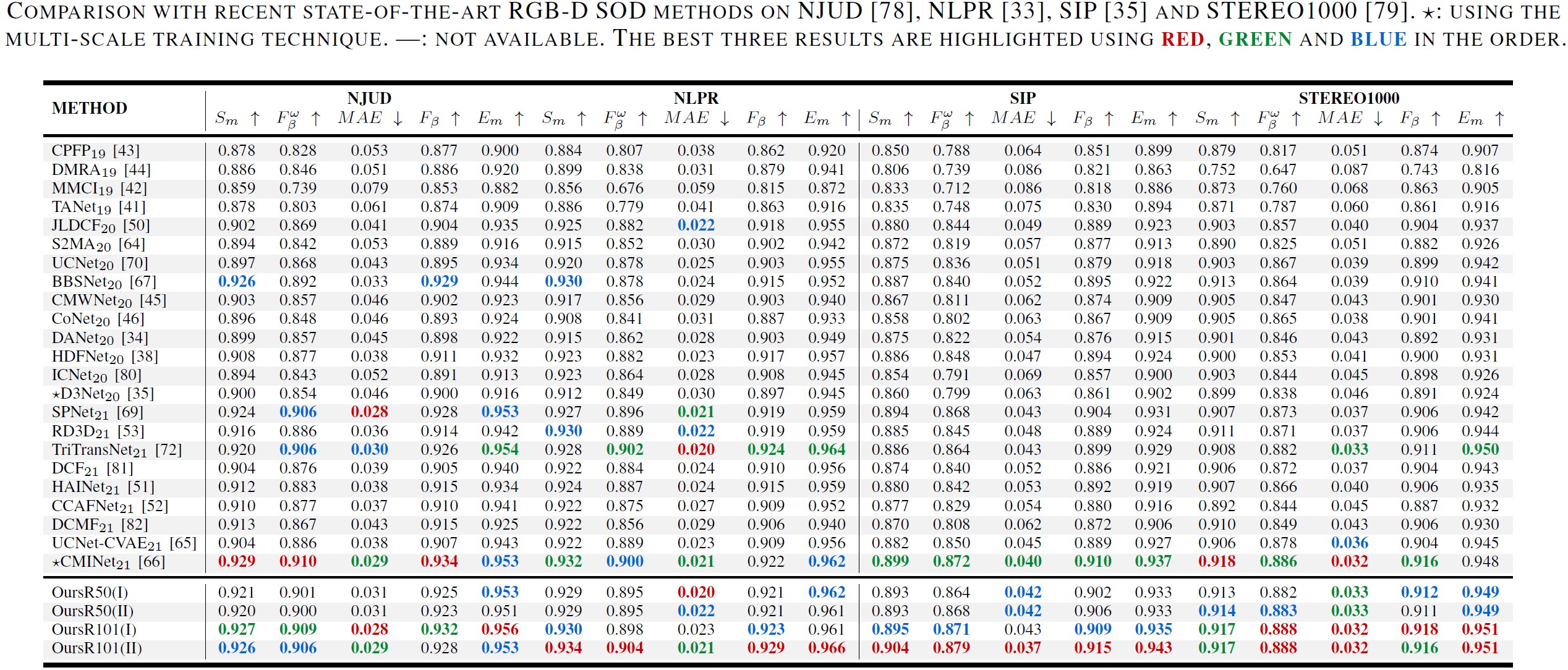
Comparison
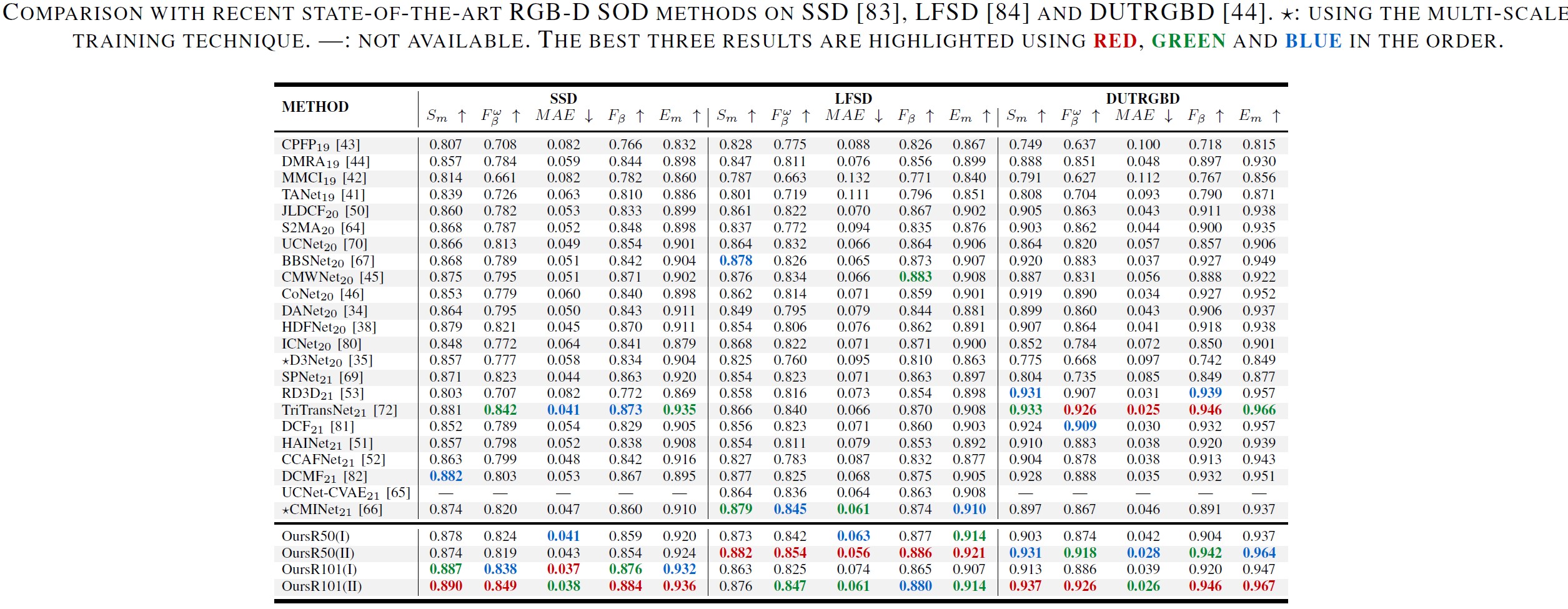
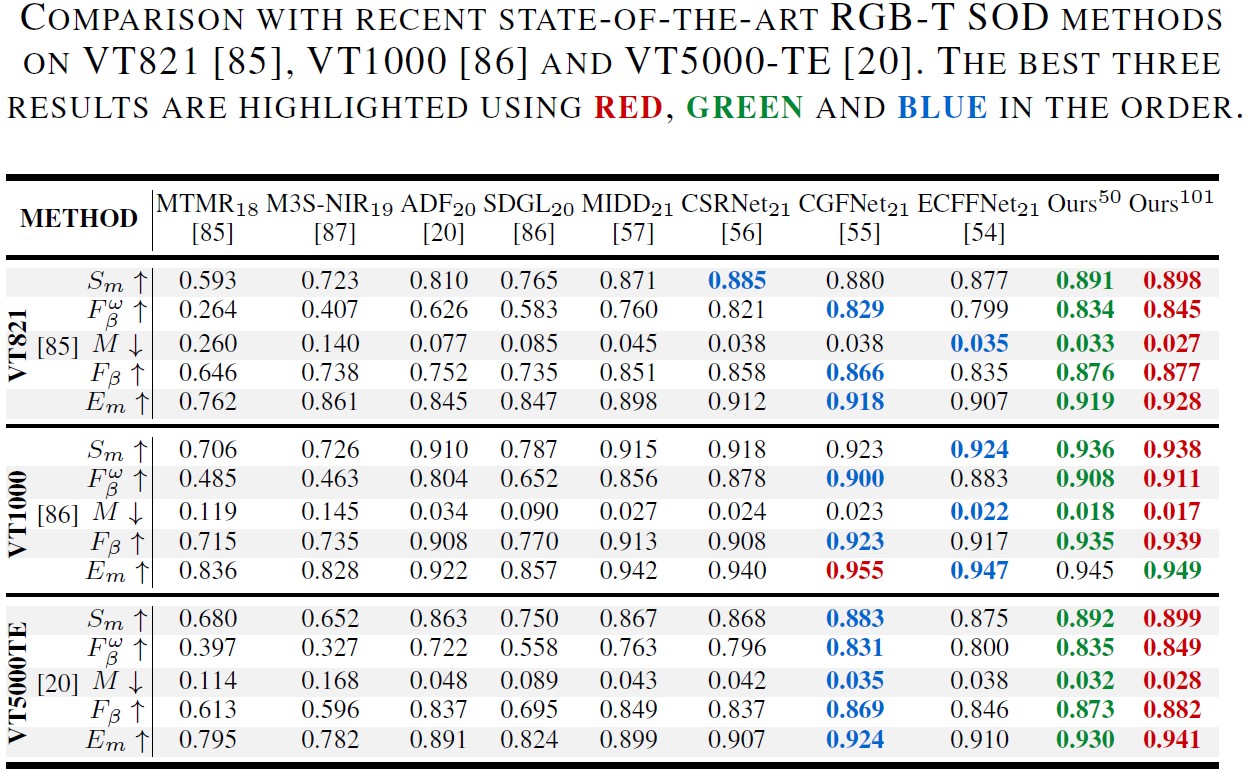
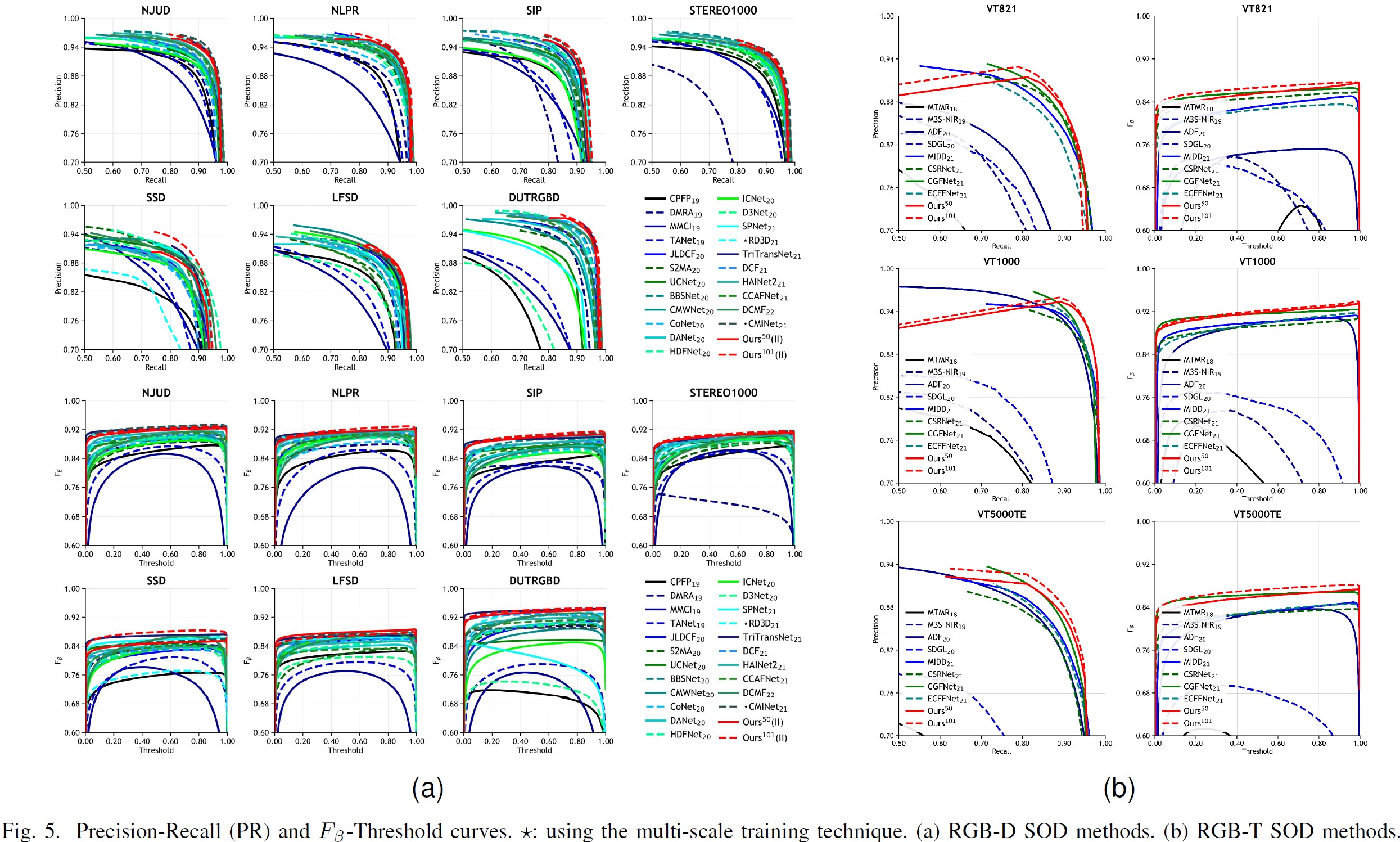
RGB-D/T SOD
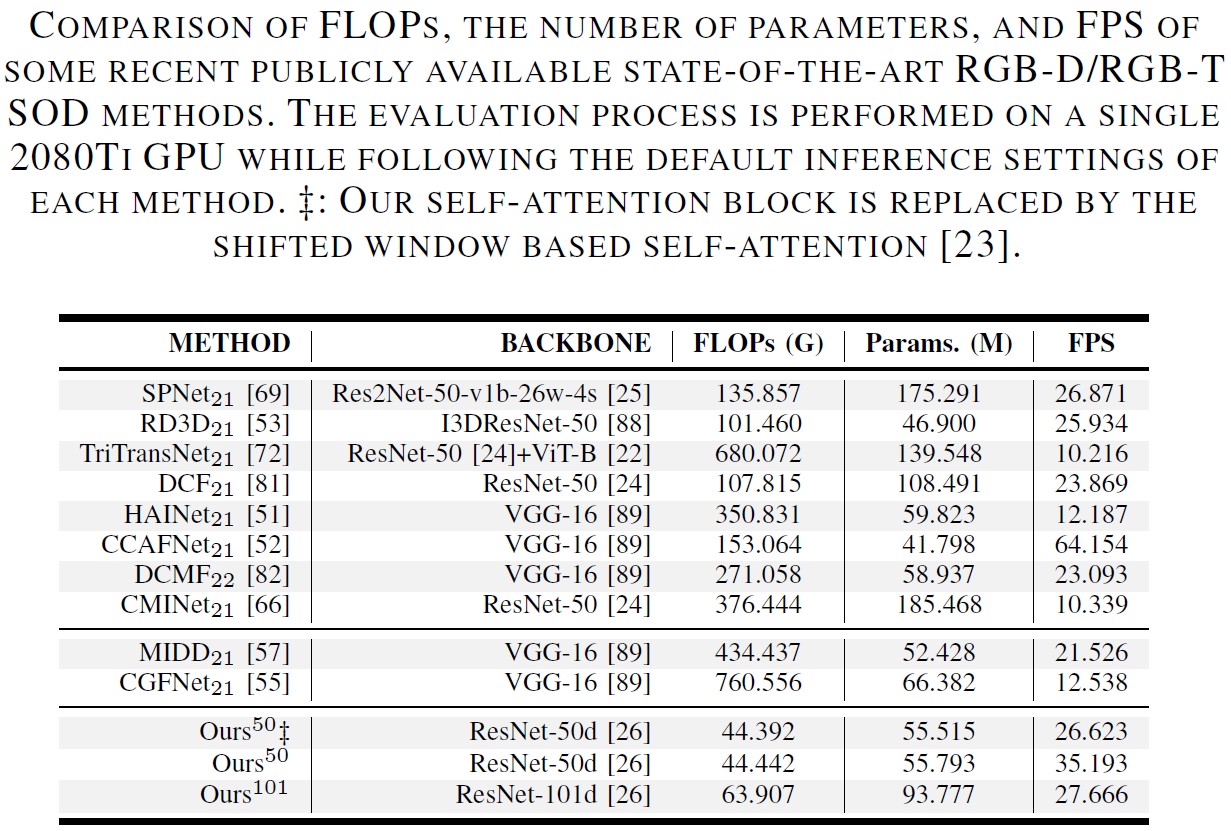
FLOPs, Parameters and FPS
Citation
@article{CAVER-TIP2023,
author={Pang, Youwei and Zhao, Xiaoqi and Zhang, Lihe and Lu, Huchuan},
journal={IEEE Transactions on Image Processing},
title={CAVER: Cross-Modal View-Mixed Transformer for Bi-Modal Salient Object Detection},
year={2023},
volume={},
number={},
pages={1-1},
doi={10.1109/TIP.2023.3234702}
}