
.
European Conference on Computer Vision (ECCV) 2024, Springer
🖐️ BibTeX (OVCOS-ECCV2024)
@inproceedings{OVCOS-ECCV2024,
title={Open-Vocabulary Camouflaged Object Segmentation},
author={Pang, Youwei and Zhao, Xiaoqi and Zuo, Jiaming and Zhang, Lihe and Lu, Huchuan},
booktitle=ECCV,
year={2024},
}
👋 Abstract
Recently, the emergence of the large-scale vision-language model (VLM), such as CLIP, has opened the way towards open-world object perception. Many works have explored the utilization of pre-trained VLM for the challenging open-vocabulary dense prediction task that requires perceiving diverse objects with novel classes at inference time. Existing methods construct experiments based on the public datasets of related tasks, which are not tailored for open vocabulary and rarely involve imperceptible objects camouflaged in complex scenes due to data collection bias and annotation costs. To fill in the gaps, we introduce a new task, open-vocabulary camouflaged object segmentation (OVCOS), and construct a large-scale complex scene dataset (OVCamo) containing 11,483 hand-selected images with fine annotations and corresponding object classes. Further, we build a strong single-stage open-vocabulary camouflaged object segmentation transformer baseline OVCoser attached to the parameter-fixed CLIP with iterative semantic guidance and structure enhancement. By integrating the guidance of class semantic knowledge and the supplement of visual structure cues from the edge and depth information, the proposed method can efficiently capture camouflaged objects. Moreover, this effective framework also surpasses previous state-of-the-arts of open-vocabulary semantic image segmentation by a large margin on our OVCamo dataset. With the proposed dataset and baseline, we hope that this new task with more practical value can further expand the research on open-vocabulary dense prediction tasks.
🚙 OVCamo

Our data is collected from existing CSU datasets that have finely annotated segmentation maps. Specifically, the OVCamo integrates 11,483 hand-selected images covering 75 object classes reconstructed from several public datasets. The distribution of the number of samples in different classes is shown in this figure.
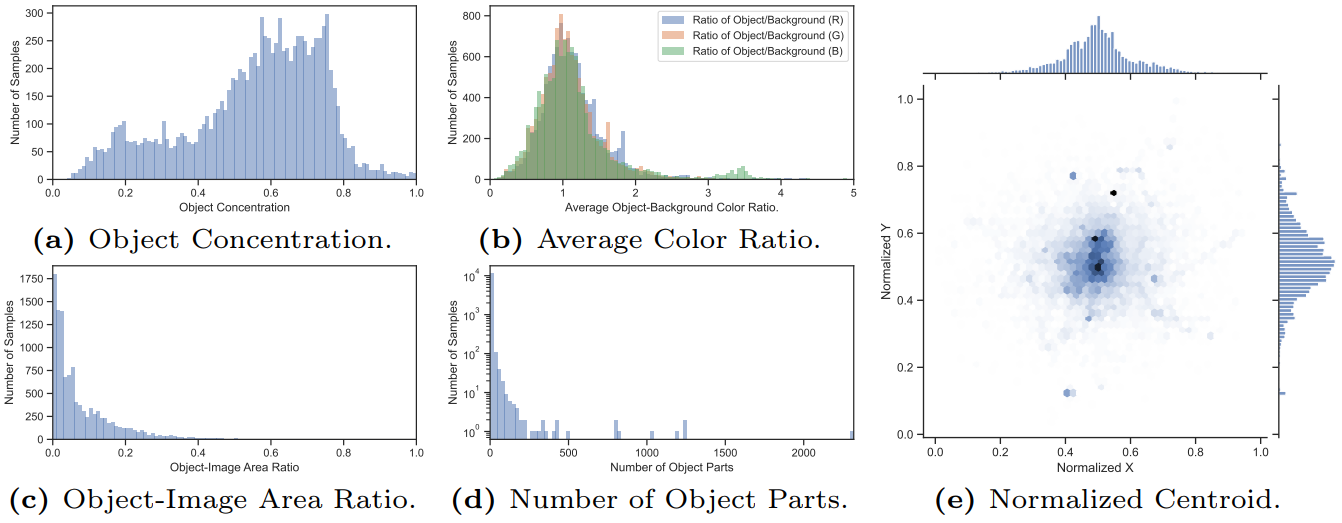
Meanwhile, we consider attributes of objects when selecting images, such as object concentration, average color ratio, object-image area ratio, number of object parts, and normalized centroid. This figure visualizes the attribute distribution of the proposed dataset. The camouflaged objects of interest usually have complex shape (a), high similarity to the background (b), and small size (c). And the image often contains multiple camouflaged objects or sub-regions with a central bias as shown in (d) and (e).

We use the alluvial graph to show the class relationships at different levels, including super, base, and sub-classes. The sub-classes shown here include class names with clearer meanings preserved from the original data and class names after initial manual correction. The base classes represent the class names obtained after careful manual filtering and merging, which was used in all the experiments in this paper. The super classes generalize the base classes from a broader perspective.
📖 OVCoser
Model

The camouflage arises from several sources, including similar patterns to the environment (e.g., color and texture) and imperceptible attributes (e.g., small size and heavy occlusion). Considering the imperceptible appearance of camouflaged objects, accurate recognition and capture actually depend more on the cooperation of multi-source knowledge. As shown in these figures, in addition to visual appearance cues, we introduce the depth for the spatial structure of the scene, the edge for the regional changes about objects, and the text for the context-aware class semantics.

We design a strong baseline OVCoser for the proposed OVCOS, based on the VLM-driven single-stage paradigm. Considering the cooperative relationship between class recognition and object perception, the iterative learning strategy is introduced to feed back the optimized semantic relationship, resulting in more accurate object semantic guidance. This top-down conceptual reinforcement can further optimize open-vocabulary segmentation performance. With the help of the iterative multi-source information joint learning strategy, our method OVCoser shows good performance in the proposed OVCOS task.
Experiment

We also visualize the results of some recent methods on a variety of data in this figure. It can be seen that the proposed method shows better performance and adaptability to diverse objects, including large objects (Col. 1-2), middle objects (Col. 3-5), small objects (Col. 6-9), multiple objects (Col. 8), complex shapes (Col. 3-5), blurred edges (Col. 1-5), severe occlusion (Col. 6), and background interference (Col. 2-6).