FasterViT: Fast Vision Transformers with Hierarchical Attention
- 论文:https://arxiv.org/abs//2306.06189
- 代码:https://github.com/NVlabs/FasterViT
- 解读:https://mp.weixin.qq.com/s/0AXri6EUrXd6Hwf2HU5Wmg
- 原始文档:lartpang/blog#18

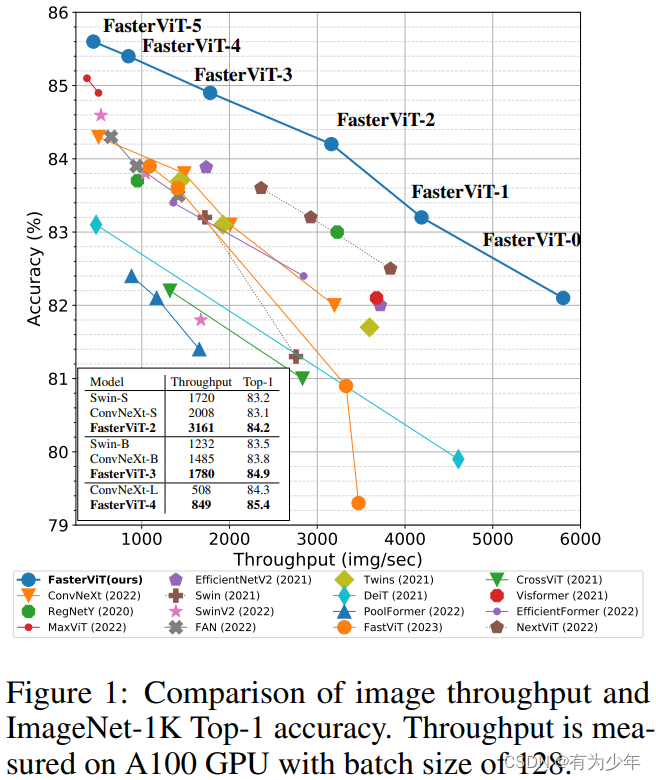
本文提出了一种 CNN 和 ViT 的混合架构,即 FasterViT。这样的混合架构可以快速生成高质量 token,然后基于 Transformer 块来进一步处理这些 token。其重点在于结合架构组合和高效的注意力模块的设计,从而优化 ViT 模型的计算效率,提高图像的吞吐率,加强对于高分辨率图像的适应能力。
模型设计
关于模型设计,作者写了一段具有参考价值的经验性分析,并在这些见解的指导下设计了所提架构,所有阶段均可从加速计算硬件受益。
我们专注于 GPU 等主流现成硬件上的计算机视觉任务的最高吞吐量这在并行计算方面表现出色。在这种情况下,计算涉及一组流式多处理器(SM),以 CUDA 和 Tensor cores 作为计算单元。它需要频繁的数据传输来计算,并可能受到数据移动带宽的影响。因此,受计算限制的操作是计算受限的,而那些受内存传输限制的操作是内存受限的。需要两者之间仔细平衡才能最大化吞吐量。
在分层视觉模型中,中间表示的空间维度随着推理过程而缩小。
- 初始网络层大多具有较大的空间维度和较少的通道(例如 112x112x64),这使它们是内存受限的。这使得这里更适合计算密集型操作,例如密集卷积而不是会增加额外传输成本的深度/稀疏卷积。也不可用矩阵操作形式表示的操作,例如非线性操作,池化,批归一化。这类操作也是内存受限的,应减少使用。
- 相反,后面层的操作往往是计算受限的,且运算成本高昂。例如,分层 CNN 具有尺寸为 14x14 的特征图和高维卷积核。这为更具表达性的操作留下了空间,例如层归一化、SE 模块,或注意力,并对吞吐量影响相当小。
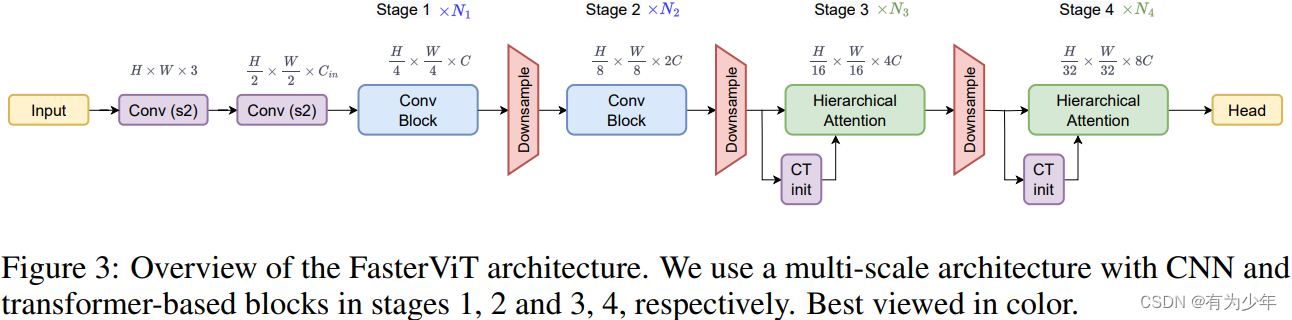
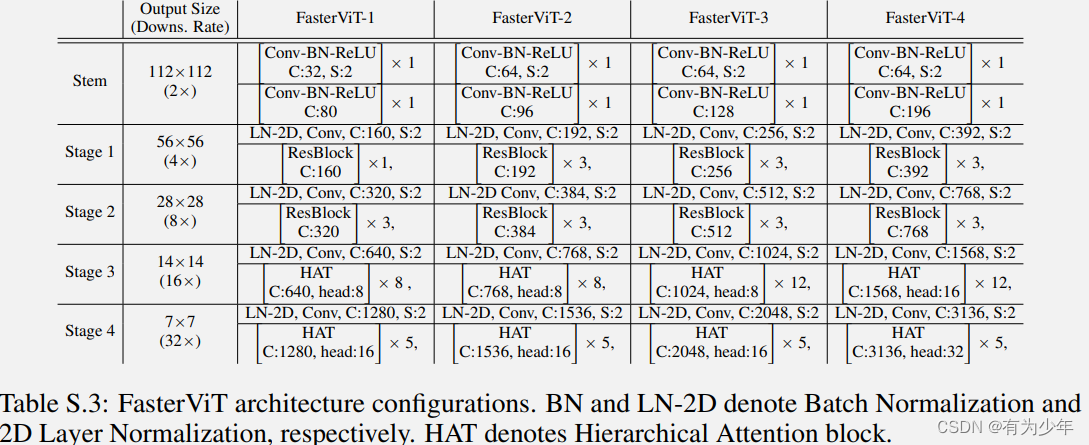
- stem 层:输入图像利用两个连续的跨步为 2 的 3x3 卷积转换为重叠的 patch。每个卷积层之后 BN 和 ReLU 被插入处理 token。
- 下采样:遵循封层结构,每个 stage 下采样 1/2。应用 2D LN 并跟一个跨步为 2 的 3xe 卷积来降低特征分辨率以及加倍通道数。
- Conv Block:在高分辨率 stage(即 stage 1、2)使用残差卷积块。
x = x + BN(Conv3x3(GELU(BN(Conv3x3(x)))))。 - Hierarchical Attention:在低分辨率 stage(即 stage 3、4)使用 Transformer 块。对于每个 Transformer 块,论文提出分层注意力块来提取长短距离空间关系,进行有效的跨窗口交互。
分层注意力 HAT
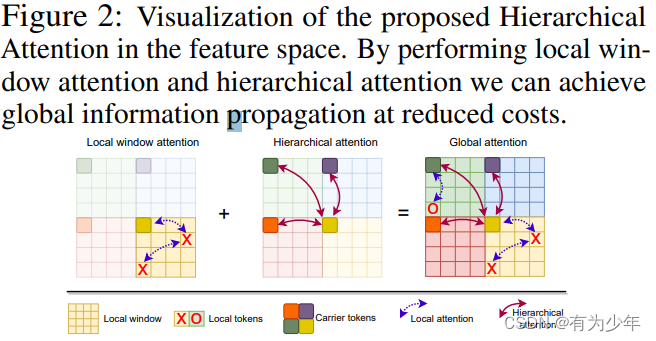
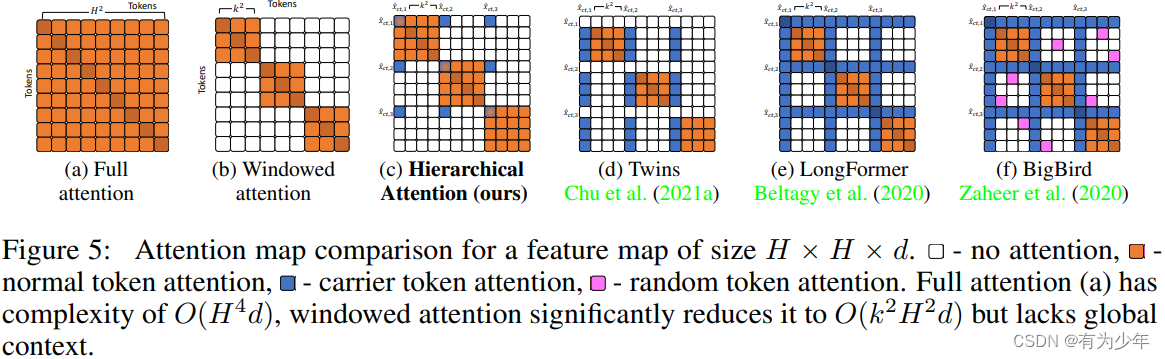
这个模块使用的是粗细 token 组合的方式进行的设计。核心即为每个局部窗口学习专用的 carrier tokens参与到窗口内部和跨窗口的信息交互,基于 carrier token 对窗口之间的交互模式进行建模。由于其通过组合有固定窗口的注局部意力和随区域数量增加而线性增加的窗口 carrier tokens,分层注意力的计算复杂度几乎随输入图像分辨率线性增长。因此,它是捕获高分辨率特征的远距离关系的高效且有效的方法。
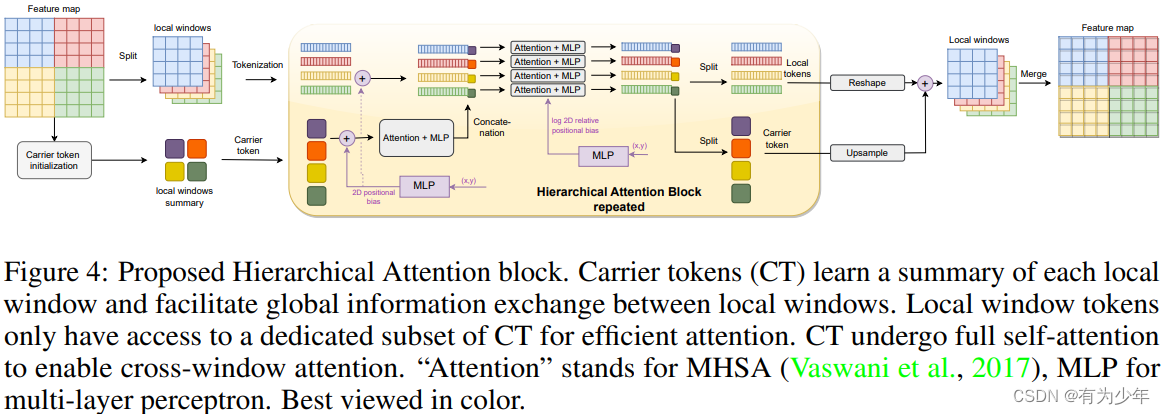
整体模块细节图如图 4 所示。在原始的局部注意力之上额外引入了与每个窗口相对应的 carrier token(CT)。这些 CT 用于总结对应的局部窗口。具体流程如下:
- 从原始的特征图中初始化 CT。这些 token 可以看做是一种更高阶的 token。初始化过程使用
卷积位置编码->平均池化的组合缩小特征空间维度。每个窗口对应生成 $L$ 个 CT($L << k$,k 是窗口的边长),共计 $n^2$ 个窗口,所以一共有 $n^2L$ 个 CT。 - CT 通过独立的序列自注意力块($x2=x1+\gamma_2(MLP(LN(x1))), x1=x+\gamma_1 MHSA(LN(x))$,$\gamma$ 是一个可学习的逐通道放缩量)总结并传播全局信息。这里由于注意力自身对位置的不敏感,所以需要引入位置编码。这里受 SwinV2 启发,利用 2 层的 MLP 嵌入 token 的绝对位置信息到特征维度上加到 CT 上。这里也对图像 token 补充了绝对位置信息。
- 局部窗口的 token 与对应的 CT 拼接后形成新的序列,计算窗口内部的序列自注意力块(与前面的类似)。实现低成本的局部和全局的信息传播。同时,为了促进图像局部归纳偏置,这里也在注意力操作中引入了来自于 SwinV2 的基于 2 层 MLP 的对数空间相对位置编码。这确保了 token 的相对位置贡献到共享的注意力模式上。这种方法在图像大小(如位置)方面具有灵活性,因为位置编码被由 MLP 插值,因此训练好的模型可以应用于任何输入分辨率。
- (CT 自己的全局交互和窗口内部的交互两部分构成了分层注意力)
- 之后将更新后的序列中局部 token 和 CT 进行拆分,并将 CT 上采样到原始分辨率,同时将图像 token 重组会原始形式。之后二者加和获得更新后的特征图。
- HAT 整体计算复杂度为 $k^2H^2d+LH^2d+\frac{H^4}{k^4}L^2d$
实验性能
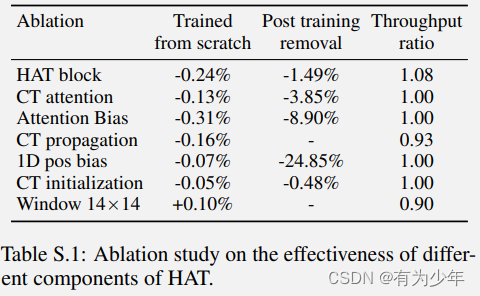
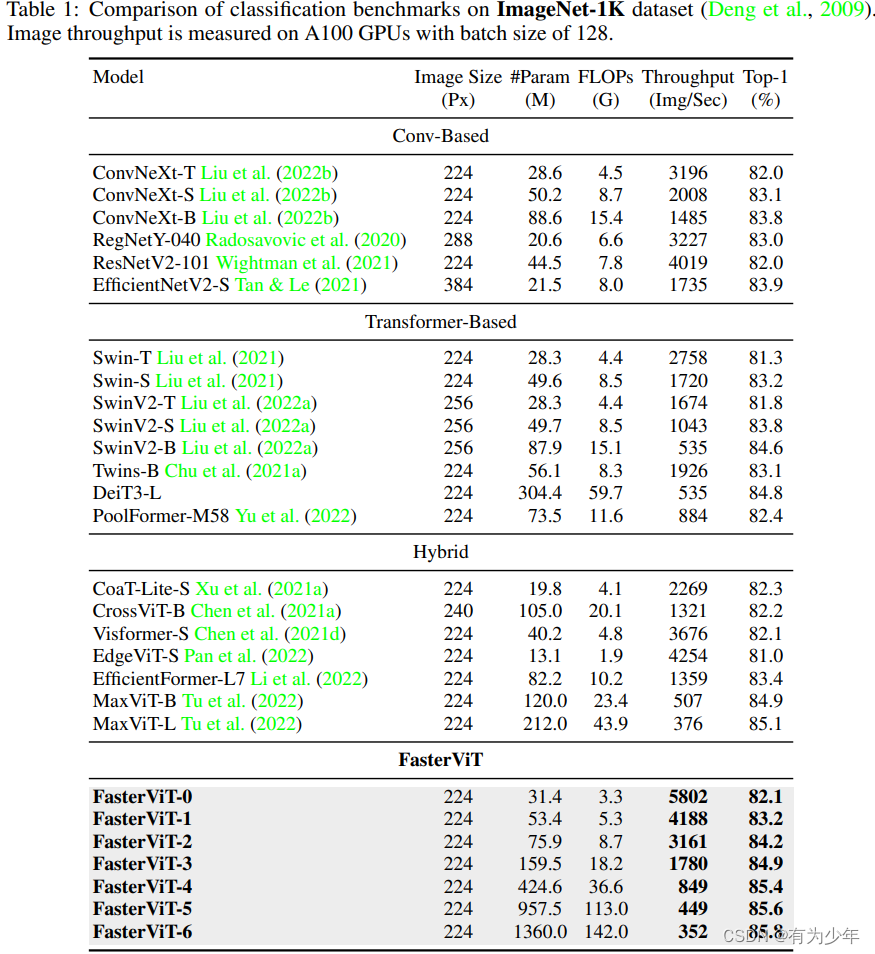
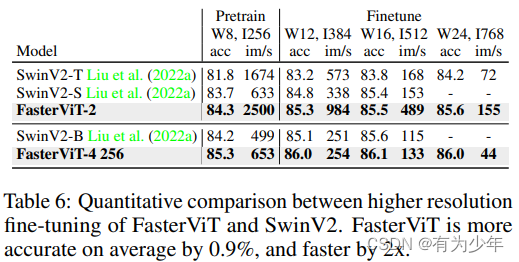
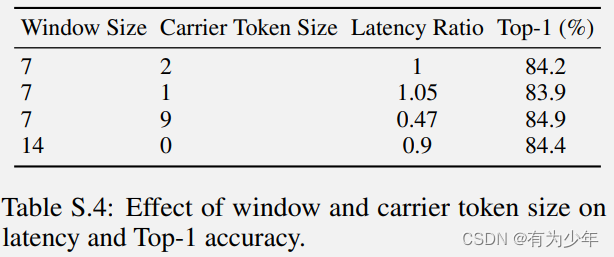
这里是在 ImageNet1K 上初始训练 256 大小(I)300 个 epoch,后面测试了使用不同的尺寸和窗口大小(W)进行微调的结果。